Sample Data & Preview#
Data sampling is a statistical analysis technique used to select, process, and analyze a representative subset of data from your dataset. The purpose is to identify patterns and trends in the larger dataset. Data sampling allows you to work with a small, manageable amount of data. This subset of the data is used to build analytical models faster and run faster than would be possible with the total amount of data.
Overview#
The Workbench provides information whether the full dats set or sample data is used. Find the information under the Flow Area. A visual indicator, that sample data is used is the '!' icon next to the dataset node within the Flow Area.
Example for full data:
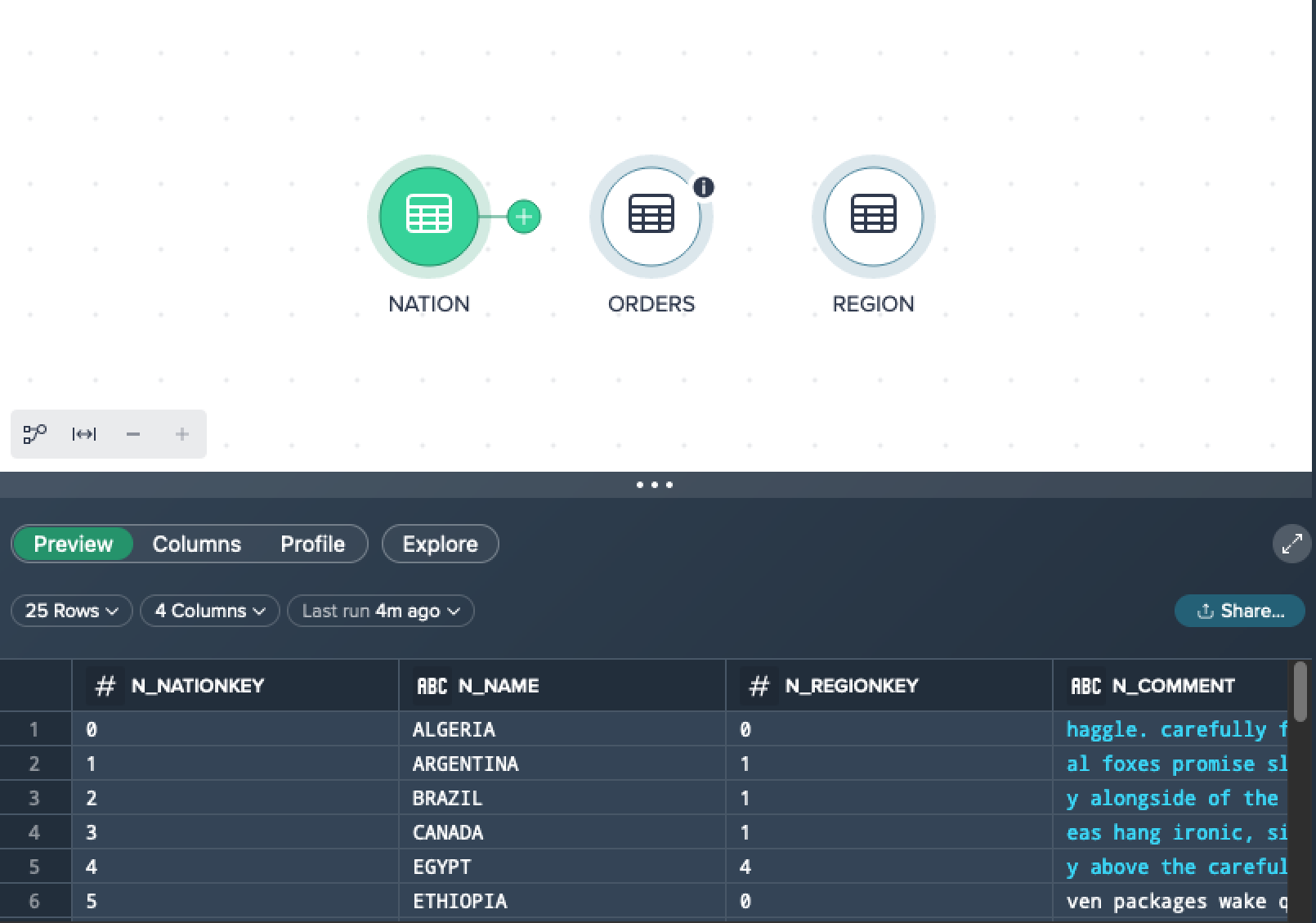
The dataset contains 25 records in total. All records are displayed and used for creating views.
Example for sample data:
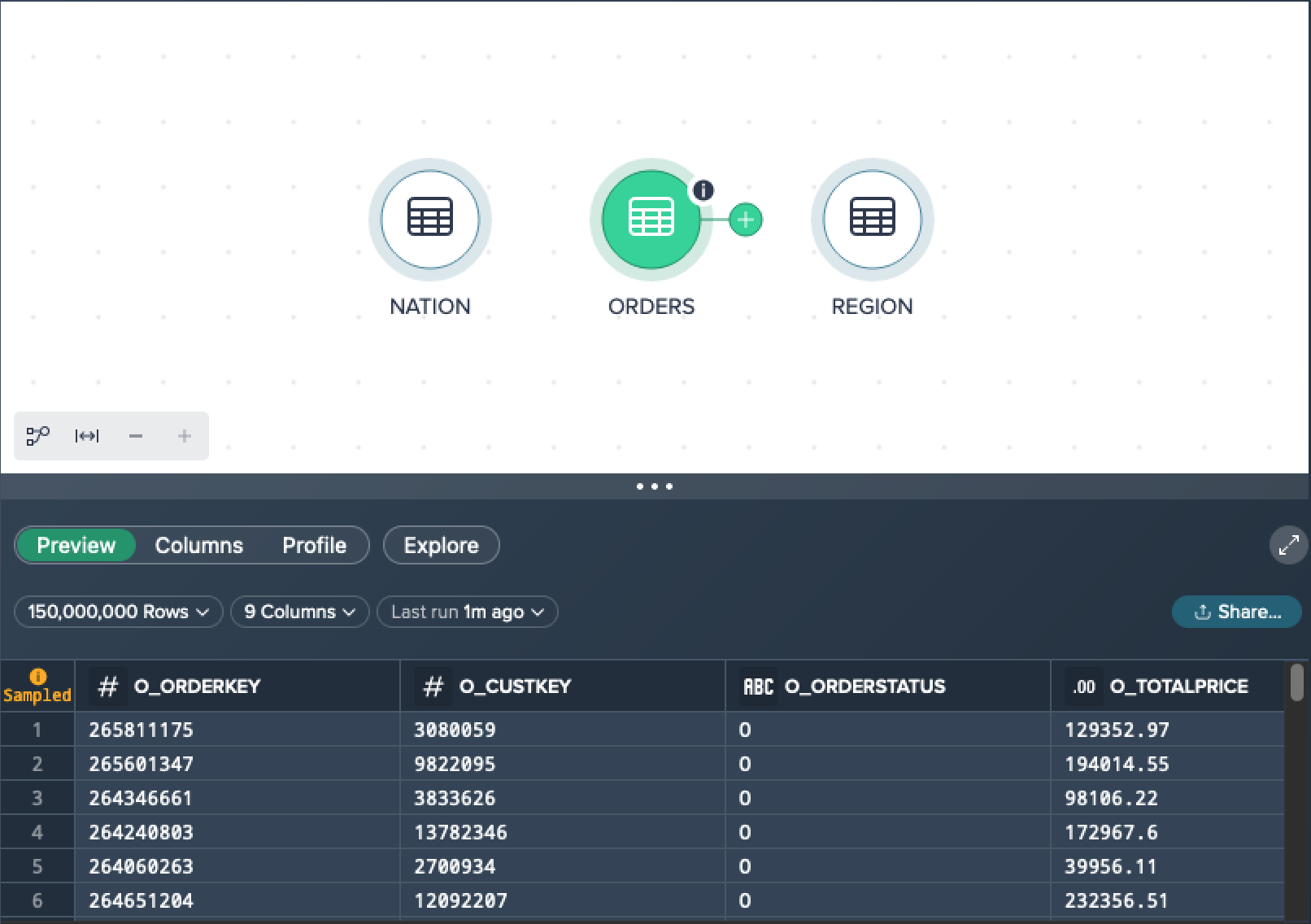
The dataset contains 150,000,000 records in total. 100,000 of the records are used to create sample data on which transformations are calculated and displayed.
Configuring Sample Data Via Custom Property#
For optimized performance and an accurate representation of your data, Datameer provides a default initial sample of 100,000 records when you start your analysis.
Datameer Admins can configure the settings for sample data usage individually. Find more information here.
Note: Increasing the values and therefore having larger samples may lower the precessing performance.
Troubleshooting#
Exhausted Preview Data#
Sometimes it can happen that you see no records in the data preview after applying an operation because of a sampled source dataset, e.g. you want to perform a Join from two huge datasets and the sample dataset has no matches but the actual full dataset has.
We recommend to perform the following temporary workaround in this case:
-
Perform the needed operation(s) to your dataset.
-
As soon as you notice that the data preview is empty, go on performing your operations anyway.
-
Validate your data with an exploration.
-
Perform further operations on the upstream dataset and not on the published table to sustain the pipeline.
-
After all operations have been performed, publish your view/ table as usual to Snowflake.
Cancelling Running Previews#
In a Project with numerous nodes, especially those involving computationally intensive transformations, the Data Grid preview can accumulate and consume significant resources in the warehouse. This situation may result in pending Snowflake queries that cannot be executed until the ongoing previews are completed. This is particularly relevant for operations such as JOIN and UNION, as well as actions performed in the SQL Editor, such as JSON extraction.
To prevent such issues, you have the option to cancel the preview at any point. Closing an editor automatically cancels any ongoing preview within that editor. Additionally, selecting a different node in the Flow Area's pipeline will cancel the preview of the previously selected node, ensuring that resources are freed up and queries can be executed promptly.