Importing Data from a Database
Databases
Relational databases include Oracle, DB2, and MySQL.
Amazon Redshift - A hosted data warehouse product, part of the larger cloud computing platform Amazon Web Services.
- DB2 – The IBM relational database management system.
- Google BigQuery - A serverless SQL data warehouse for the cloud.
- Greenplum - An open-source massively parallel processing (MPP) database.
- MSSQL – A relational database based on structured query language.
- MySQL – A relational database based on structured query language. You need to provide the hostname using a syntax such as 123.45.67.89 or anyhost.com. In addition, you need to provide the database name, user name, and password.
Oracle – A relational database management system designed for grid computing inclusive CLOB support for importing data.
- Netezza- A column-oriented database management system.
- PostgreSQL - An object-relational database management system (ORDBMS).
- Snowflake - A SQL data warehouse for the cloud.
- Sybase IQ - A column-based relational database software.
- Teradata 13 - A relational database based on structured query language.
- Vertica - A grid-based and column-oriented analytic database software.
HSQL (file) – is a lightweight, 100% Java SQL Database Engine. You need to provide the database name you want to use, the username, and password.
Before being able to import data from a database, an administrator needs to Install Database Drivers.
Importing a Job from a Database
To import data from a database you need to have a database connection configured in Datameer.
After you have your connection configured:
- Click the + (plus) button and select I mport Job or right-click in the browser and select Create new > Import job.
- Click Select Connection, select your database connection and click Select. After you have selected the database connection, click Next.
Select the Table, View, or Enter SQL.
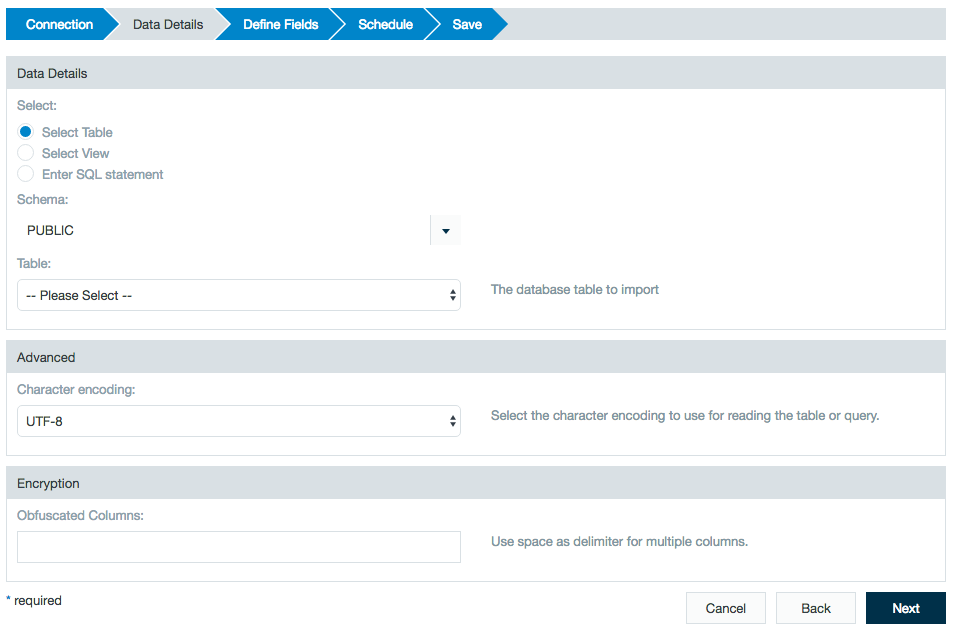
Notes for database data details
The drop-down box for tables and views has a hard limit of 1,000 entries.
The schema selection option is available to filter table names for the following database types:
- MSSsql
- Oracle
- Postgre
- PostgreSQL82/Greenplum
- Netezza
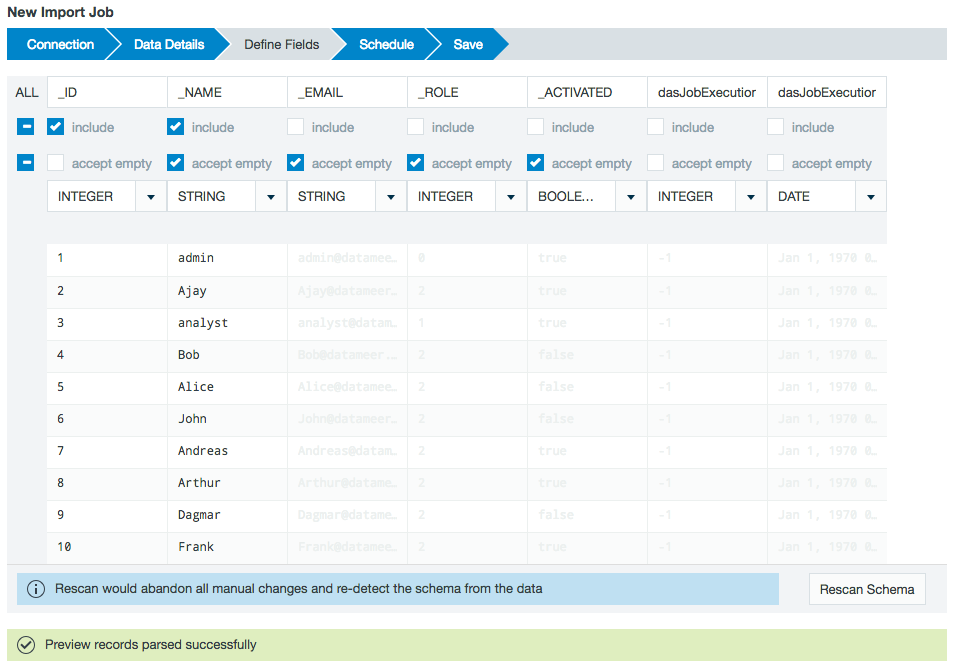
View a sample of the data set to confirm this is the data source you want to use. Mark the checkboxes to select which fields to import into Datameer. You can also specify the format for date fields. Click the help link question mark to see a complete list of supported formats. You can specify the data type using the list box as shown.
To enable parallel loading of the table, Datameer uses the chosen column to segment rows into unique subsets. Good options to split the column include primary keys, auto-increment columns, or unique indexed columns. The column type should be a number or date.
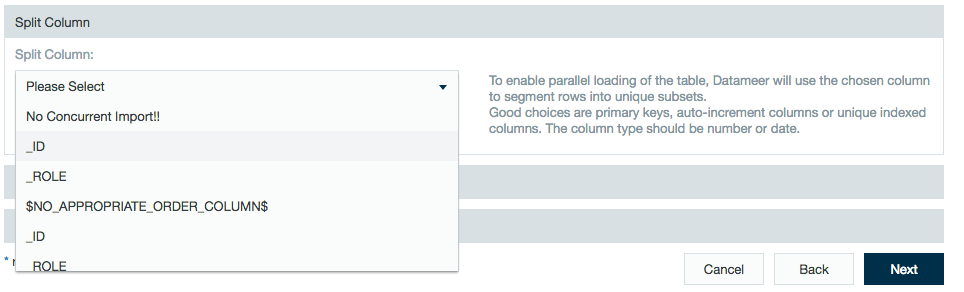
The import uses a single select statement if a split column isn't defined, even if the limit of mappers is configured to a higher number.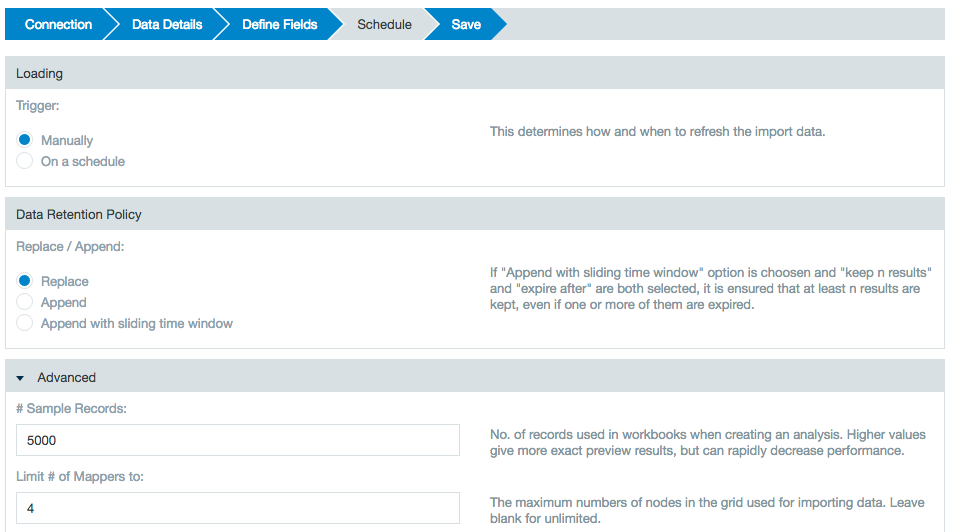
You can see the difference in behavior within the job log.
Single splitINFO ... (JdbcSplitter.java:70) - number of desired splits: 4 INFO ... (JdbcConnector.java:150) - connected to '<connection_string>' with schema set to 'null' WARN ... (DataDrivenSplitStrategy.java:138) - creating single split because splitColumn is set to '$NO_APPROPRIATE_ORDER_COLUMN$' INFO ... (JdbcSplitter.java:104) - 1 JdbcSplits: INFO ... (JdbcSplitter.java:106) - SELECT {"id", bytes_processed", ...} FROM ...After defining an appropriate split column for the import job, it is processed in parallel.
Multiple splitsINFO ... (JdbcSplitter.java:70) - number of desired splits: 4 INFO ... (JdbcConnector.java:150) - connected to '<connection_string>' with schema set to 'null' INFO ... (JdbcConnector.java:356) - SELECT (SELECT MIN("id") FROM "dap_file"."id") AS MIN_VALUE, (SELECT MAX("id") FROM "dap_file"."id") AS MAX_VALUE FROM DUAL INFO ... (JdbcSplitter.java:104) - 4 JdbcSplits: INFO ... (JdbcSplitter.java:106) - SELECT {"id", bytes_processed", ...} FROM "dap_file" WHERE {...} ... INFO ... (JdbcSplitter.java:106) - SELECT {"id", bytes_processed", ...} FROM "dap_file" WHERE {...} ... INFO ... (JdbcSplitter.java:106) - SELECT {"id", bytes_processed", ...} FROM "dap_file" WHERE {...} ... INFO ... (JdbcSplitter.java:106) - SELECT {"id", bytes_processed", ...} FROM "dap_file" WHERE {...} ...- Define the schedule details, specify whether to replace or append data, and click Next.
With a database import job, under the heading Data Retention Policy, if you select to append (with or without the time window) you have the option to select to enable an incremental mode.
Incremental mode only imports rows that contain values in the split column greater than the maximum value from the previous import run.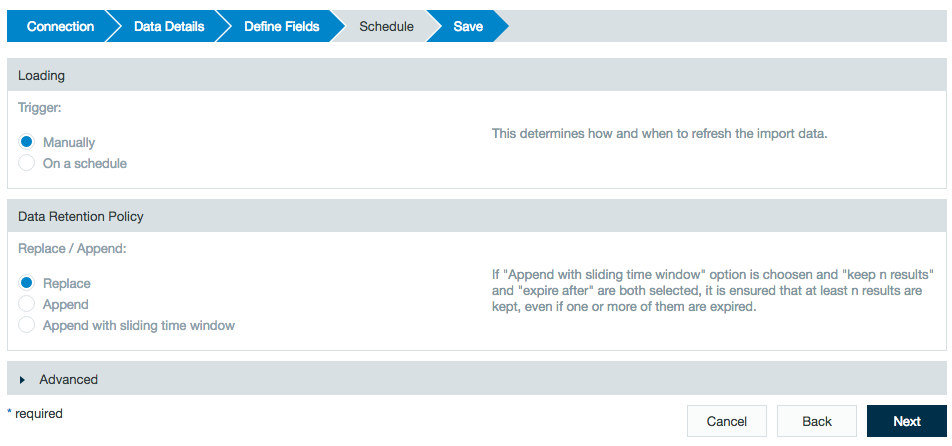
Add a description and click the checkbox to start the import immediately if desired Click Save when finished.
You can also specify notification emails to be sent for error messages received and when a job has successfully run.
Give the new import job a name and then click Save.
- The import job data is now accessible from the browser.
Adding a SQL Statement as a Data Source
Datameer allows you to directly enter a complete custom SQL Query as a data source.
To add a SQL Query as a data source:
- When on the Data Details page, select Enter SQL statement.
Add your SQL Query to the field and click Next. If the custom select query contains column aliases specified using single quotation mark, then the alias is used as column name instead the original name. For better performance, run custom SQL queries in parallel by adding a split column in the WHERE clause of the SQL statement.
For example, if you enter the following:SELECT abs AS 'absolute', v1 AS 'valueOne' FROM 'schema.table' WHERE $id_col$ and field2 = 34;
Column names are:
absolute, valueOne
The split column in the above SQL example is named
id_col. Wrap it in the $ marks as shown. Next, use normal SQL syntax to add additional criteria in the WHERE clause as shown in the example.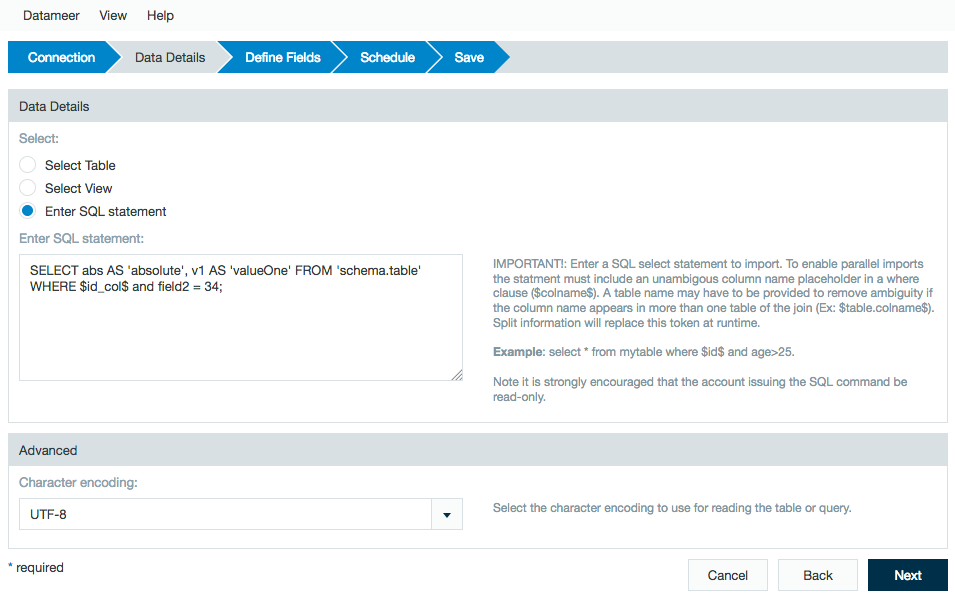
There might be also more advanced queries possible. (Learn more about Job History)Datameer Job HistorySELECT dap_job_configuration.id JobConfID, CASE dap_job_execution.job_status WHEN 0 THEN 'QUEUED' WHEN 1 THEN 'RUNNING' WHEN 2 THEN 'COMPLETED' WHEN 3 THEN 'ERROR' WHEN 4 THEN 'COMPLETED_WITH_WARNINGS' WHEN 5 THEN 'WAITING_FOR_OTHER_JOB' WHEN 6 THEN 'CANCELED' WHEN 7 THEN 'ABORTING' WHEN 8 THEN 'WAITING' ELSE 'OTHER' END JobConfStatus, dap_job_execution.id, dap_job_execution.start_time, dap_job_execution.stop_time, dap_file.name, dap_job_execution.user, TIMEDIFF(dap_job_execution.stop_time, dap_job_execution.start_time) Duration FROM dap_job_configuration INNER JOIN dap_file ON dap_job_configuration.dap_file__id = dap_file.id INNER JOIN dap_job_execution ON dap_job_configuration.id = dap_job_execution.dap_job_configuration__id- Follow steps 4-7 as seen above to complete the new import job.
This open ability in allowing input of SQL is a security risk to possible data corruption. Datameer has a basic check system to help prevent data corruption but strongly recommends the account should be READ ONLY and only have access to required tables/views unless the user has professional experience with SQL statements.
LIMIT
Datameer internally sets a LIMIT which can cause an error if the user creates a MySQL query which also uses LIMIT. In order to use LIMIT to find a specified range of results, parentheses need to be added to your query. Example: '(SELECT * FROM table LIMIT 0,10)'